【導入実証(PoC)事例】
長文日本語入力に対する応答速度の改善
限られたハードウェアリソースでの
応答速度改善を検証
何度もAIとのやりとりをおこなっていると、応答が遅く感じられることがあります。
これは、過去のやり取りが蓄積するにつれ、AIが処理すべき情報量が増えるためです。
Nextorageでは、PhisonのaiDAPTIV+をオンプレミス環境に導入し、英語よりもトークンが多くなりがちな(文章を構成する最小単位)日本語における応答速度を改善できるかを検証しました。
その結果、aiDAPTIV+を有効にすることで、応答開始速度(TTFT)が約10倍高速化。特に128トークン以上の長文では、明確な速度改善が確認されました。
小型AIサーバー(Jetson Orin Nano)上でもこの効果が得られたことから、省スペース・低コスト環境でも実用的なAI応答システムを構築できる可能性を示す結果となりました。
1. 背景と課題
多くの企業では、製品マニュアルやFAQ、社内ドキュメントなどをAIに学習させ、自然言語で検索・回答できる仕組みの導入が進みつつあります。
しかし、GPU性能が限られたオンプレミス環境では、応答までに時間がかかるという課題がありました。
この課題に対し、NextorageはaiDAPTIV+を用いることで、限られたハードウェアリソースでも高速な応答を実現できるかを検証しました。
2. 検証の目的
- 企業における各部門の持つナレッジベース(*基礎的な特性を収集)に対して、aiDAPTIV+が応答速度をどの程度改善できるかを同じプロンプトによる質問を繰り返すことで確認
3. 実施環境・構成
ハードウェア:Jetson Orin Nano
メモリ:7.4 GiB
OS:Ubuntu 22.04.5 LTS
AIモデル:Llama-3.2-3B-Instruct-GPTQ / RakutenAI-2.0-mini-instruct / gemma-2b-it-gptq
4. 測定項目
TTFT*(Time to First Token)、推論時間、入力トークン長、出力トークン長
*TTFTとは:ユーザーが質問を送信してから、AIが最初の言葉を返すまでの時間を指します。
5. 結果
(1) AIモデル:Llama-3.2-3B-Instruct-GPTQの推論時間比較
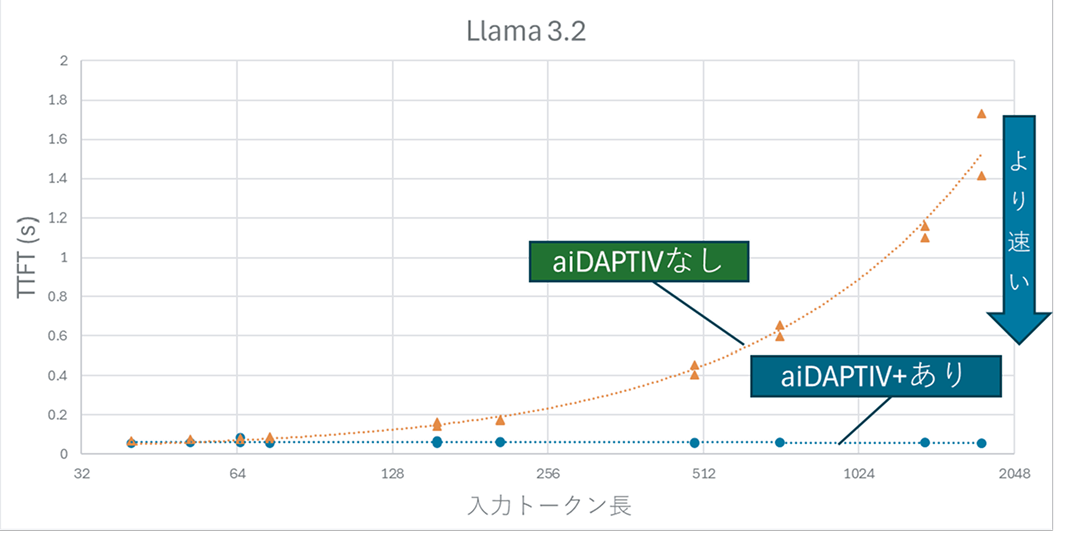
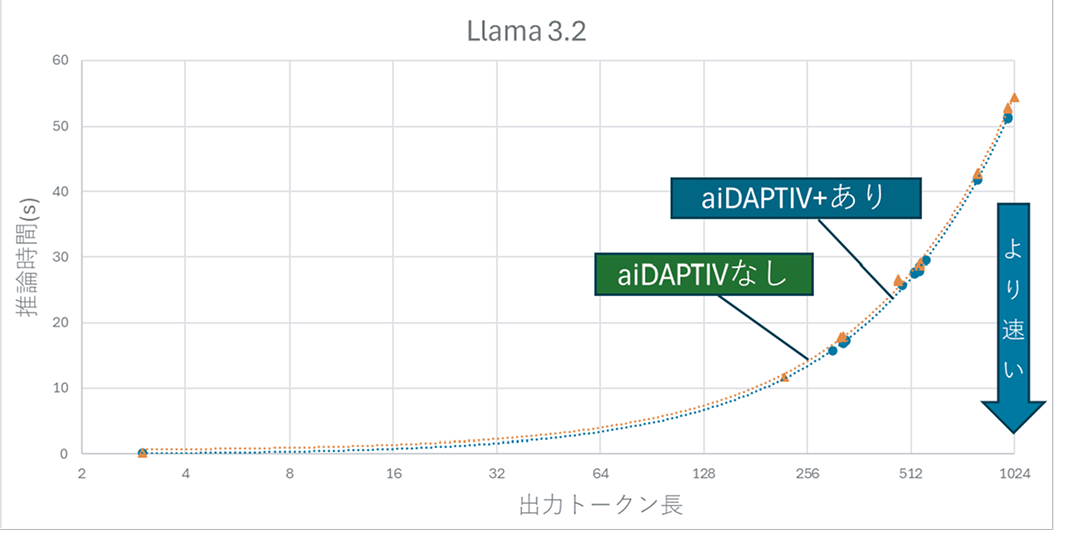
- aiDAPTIV+ありでは0.1秒以下を維持し、約10倍の高速化を確認。
- 出力トークン(AIの回答文)長による影響はほとんどなし。
(2) AIモデル:RakutenAI-2.0-mini-instructの推論時間比較
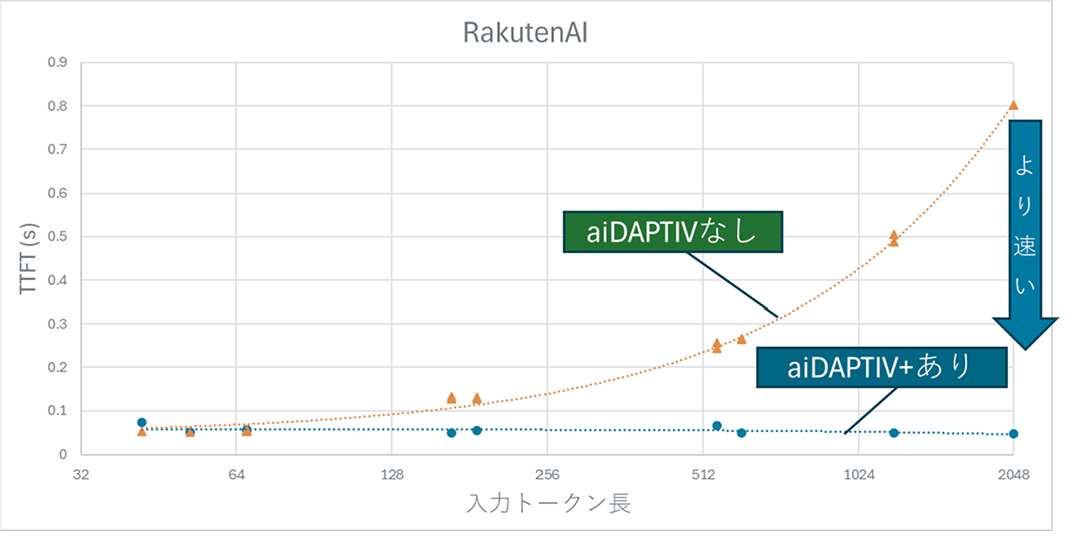
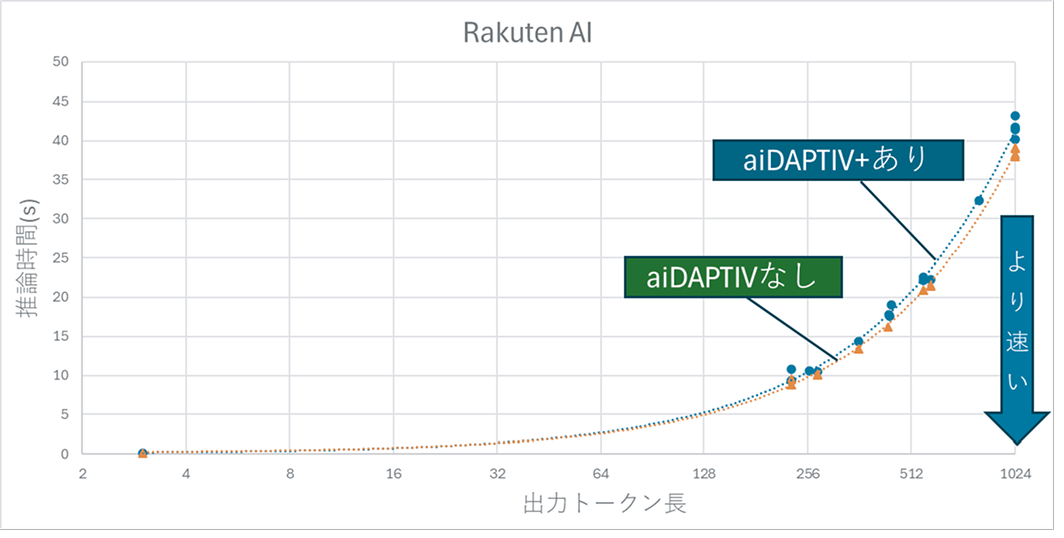
- 1024トークン以上で、aiDAPTIV+なしでは0.5秒超の遅延。
- aiDAPTIV+ありでは0.1秒以下で安定。
- 改善効果はLlamaモデルよりやや小さいが、体感上は十分な応答速度。
- 出力トークン長による影響はほとんどなし。
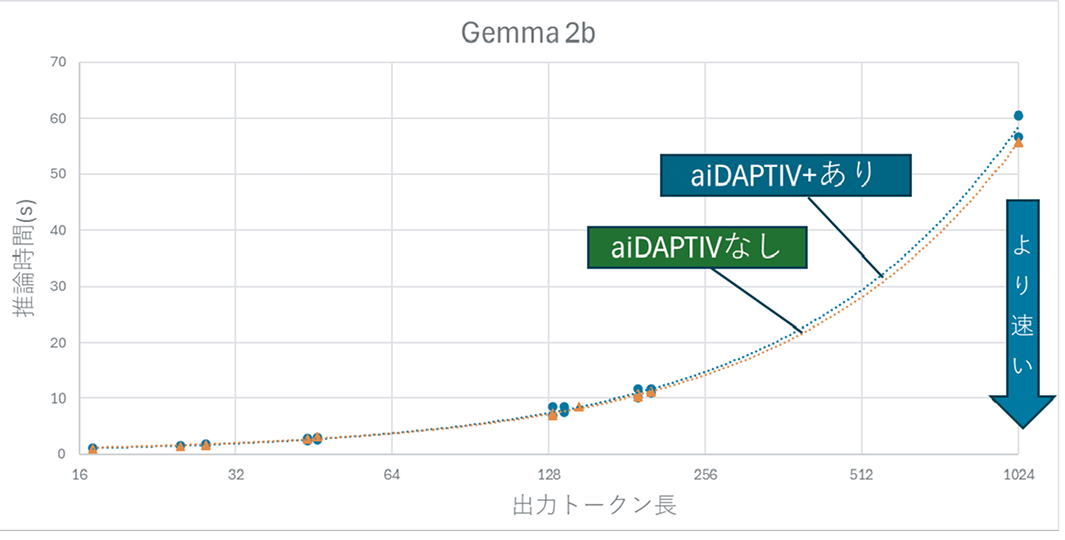
(3)AIモデル:gemma-2b-it-gptqの推論時間の比較
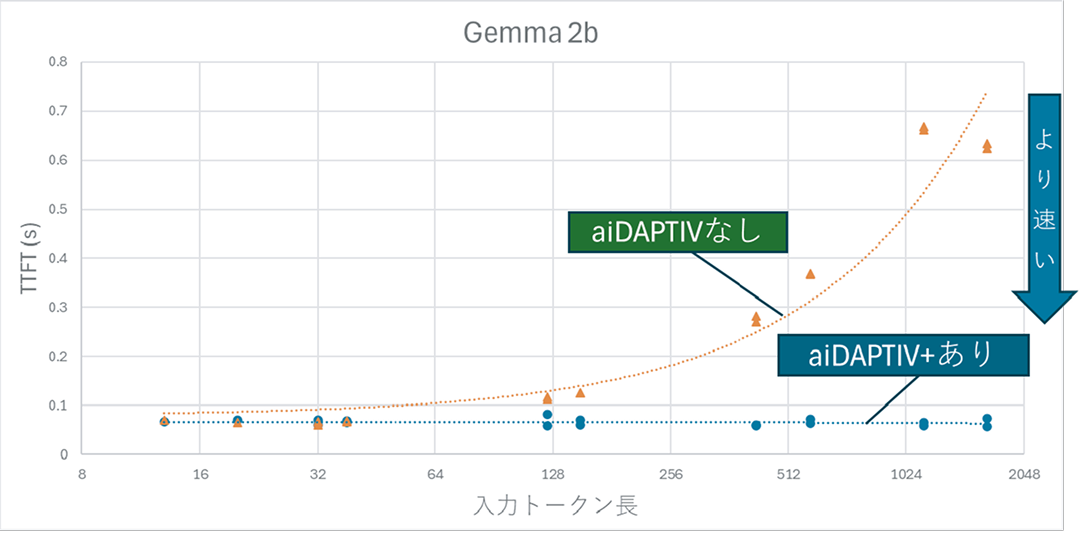
- 入力トークン1024以上でaiDAPTIV+なしでは0.5秒超の遅延。
- aiDAPTIV+ありでは0.1秒以下を維持し、TTFTの明確な改善を確認。
- 出力トークン長に対する影響は見られず、
- 入力の長さが長いほどaiDAPTIV+の効果が発揮される傾向を確認。
まとめ
- aiDAPTIV+の導入により、128トークン以上の長文日本語入力で応答速度が改善することを確認。
- 出力トークンに対しては、トークン長によらず改善は認められない。
- 今後は、ドメイン・タスクに特化した内容での評価を行う必要がある。
あなたの課題を一緒に検証しませんか?
Nextorageでは、企業様の業務に即した PoC をご提案し、aiDAPTIV+ の導入可能性を共に検証いたします。
対象企業例
- サポート業務、営業支援、資料生成、ナレッジ検索、異常検知など AI 活用を検討している企業
- 機密性が高くクラウド対応が難しいデータを扱う企業
- GPUコストを抑えて自社内でAIを運用したい企業
PoC支援内容例
- データ整理/前処理支援
- モデル学習構築・評価支援
- 導入環境構築支援
- 成果評価・報告書作成
まずはお気軽にご相談ください。